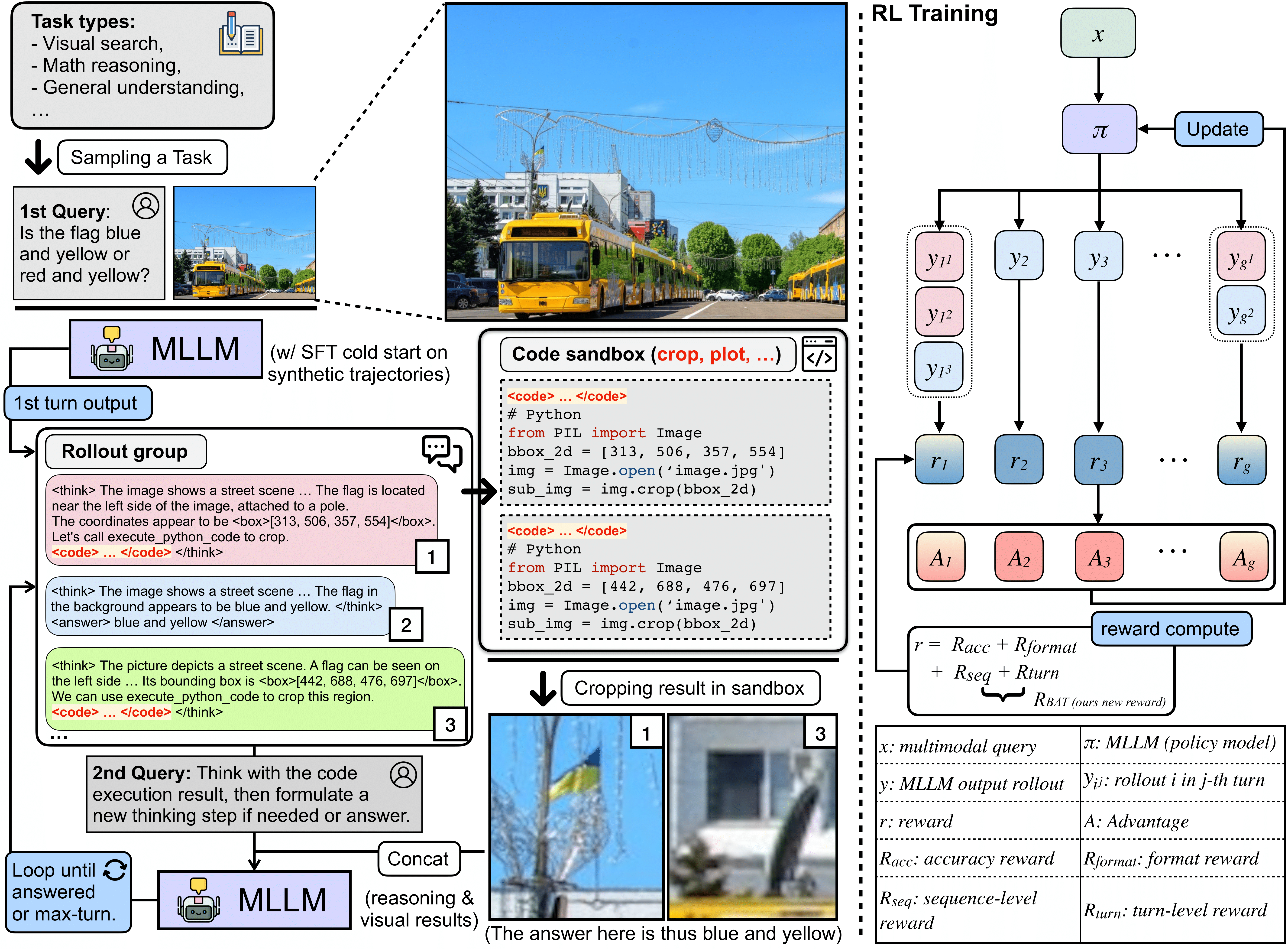
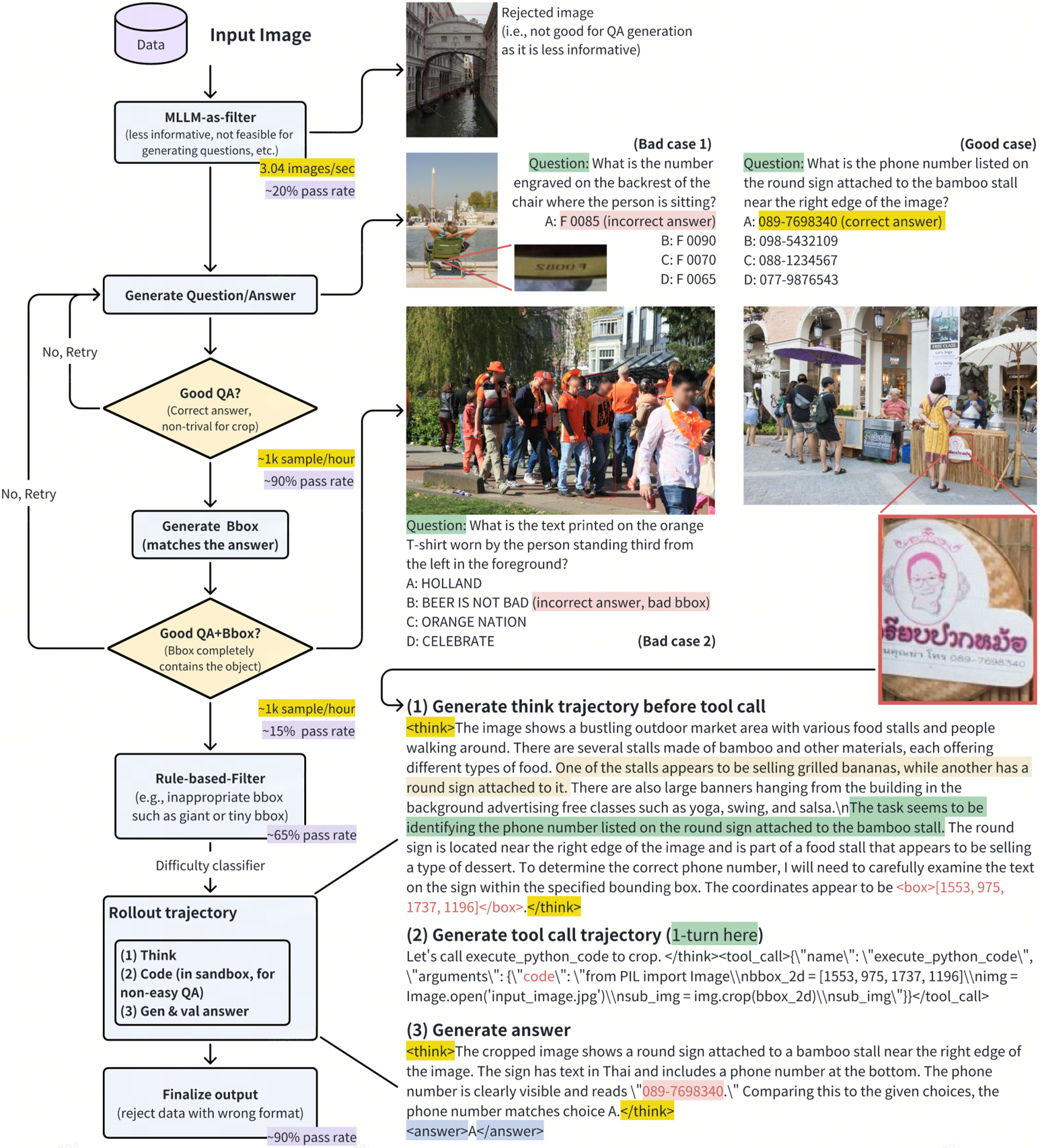
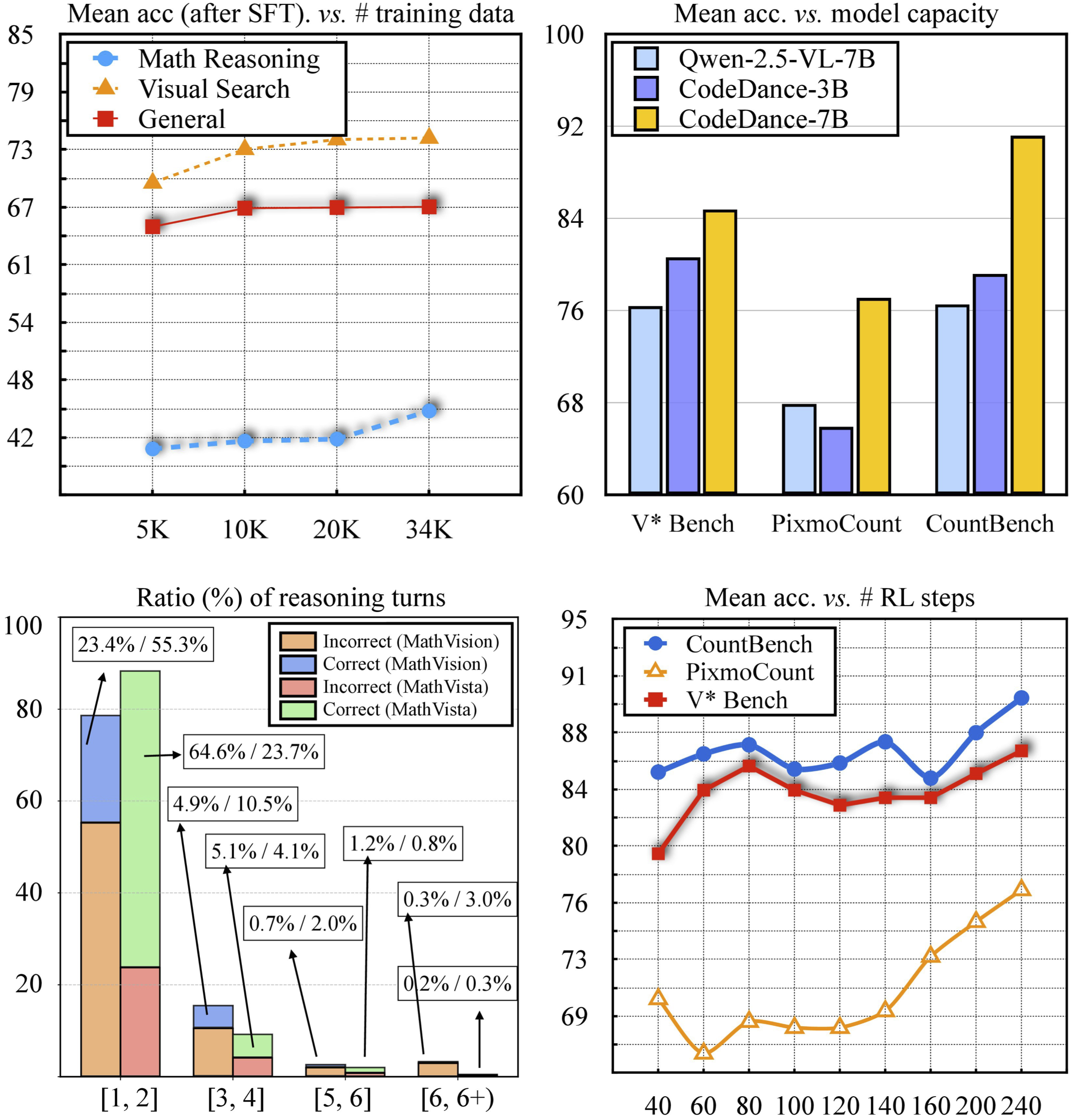
♫ Dynamic, Difficulty-aware, visual tool-calling
CodeDance dynamically invokes tools according to task difficulty to prevent both tool underuse (unable to invoke tools on challenging tasks) and tool overuse (redundant calls on easy tasks).
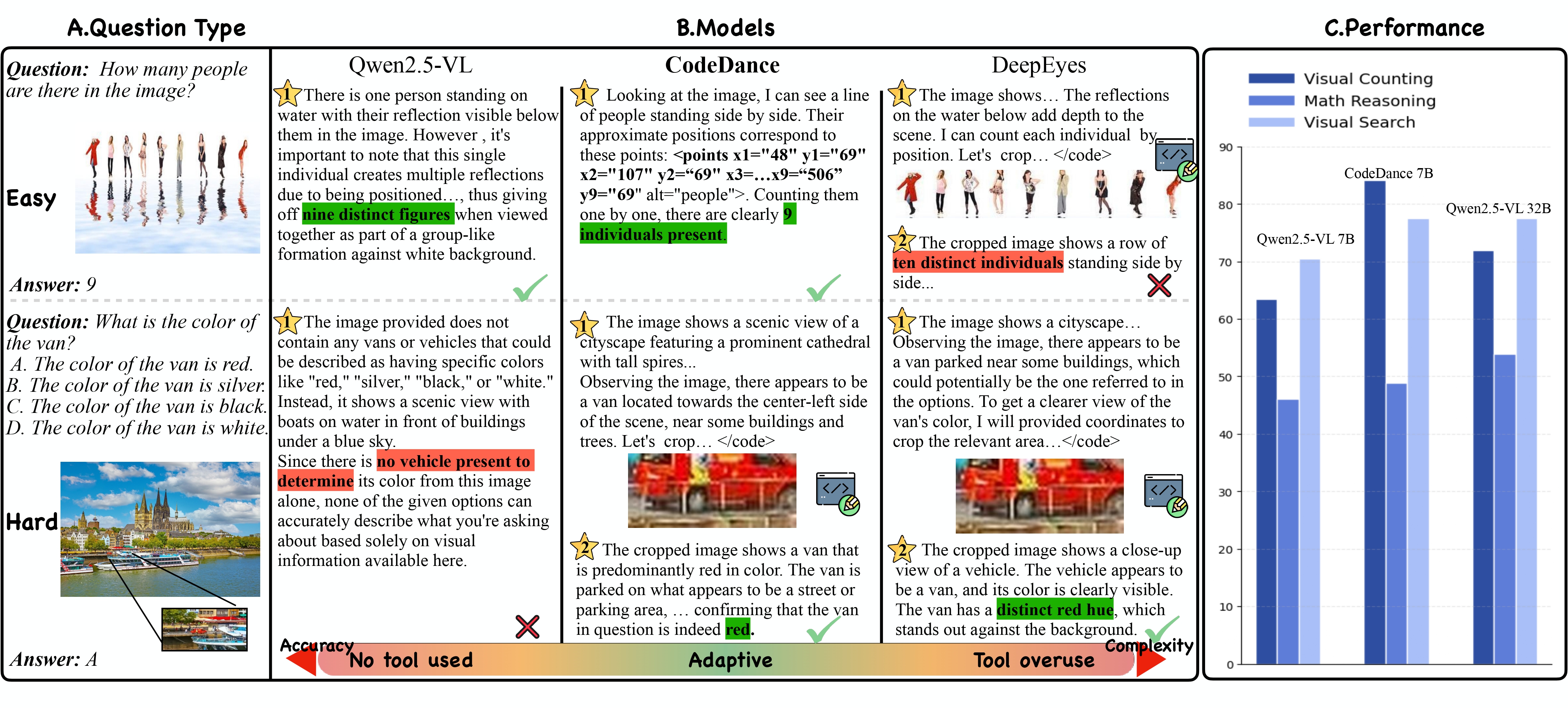
|
Motivation and effectiveness of dynamic tool invocation in CodeDance. Left: qualitative examples show that both tool underuse (unable to invoke tools on challenging tasks) and tool overuse (redundant calls on easy tasks) lead to hallucinated reasoning, incorrect answers, and unnecessary complexity (more reasoning turns and longer rollout time), whereas CodeDance dynamically invokes tools according to task difficulty to obtain correct solutions. Right: quantitative results show CodeDance-7B consistently surpasses all Qwen2.5-VL-7B baselines and exceeds the 32B version and GPT-4o on several tasks. |